

Retrieval-Augmented Generation (RAG) คือเทคโนโลยีที่ผสมผสานระหว่างการค้นคืนข้อมูล (Retrieval) และการสร้างข้อความ (Generation) เข้าด้วยกัน เพื่อเพิ่มประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (LLM) ให้สามารถให้คำตอบที่แม่นยำและอ้างอิงข้อมูลจริงได้ดีขึ้น
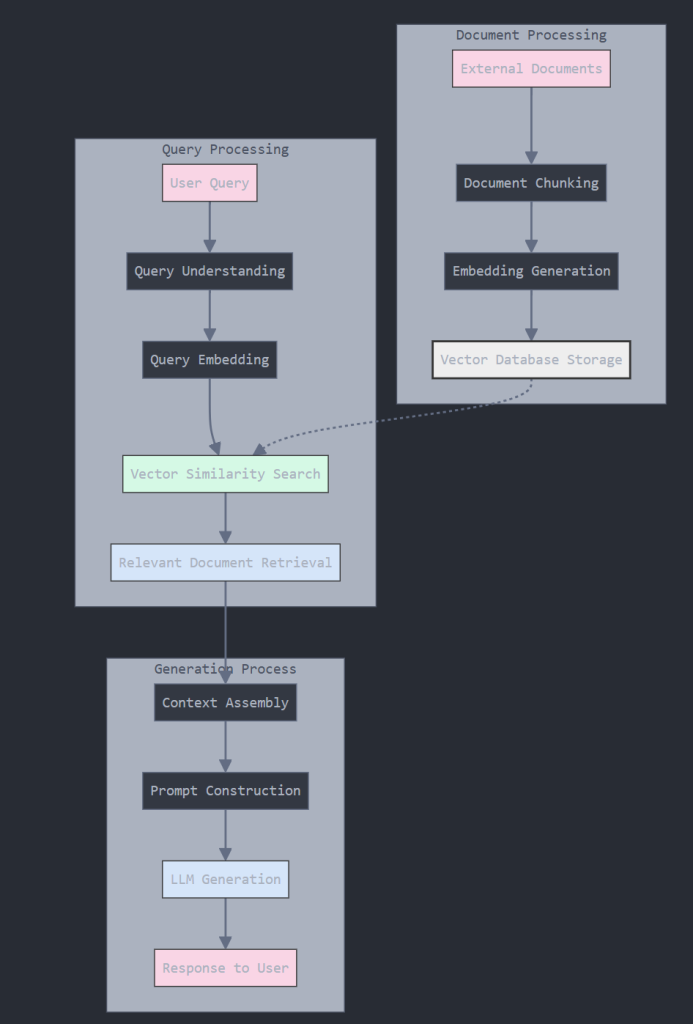
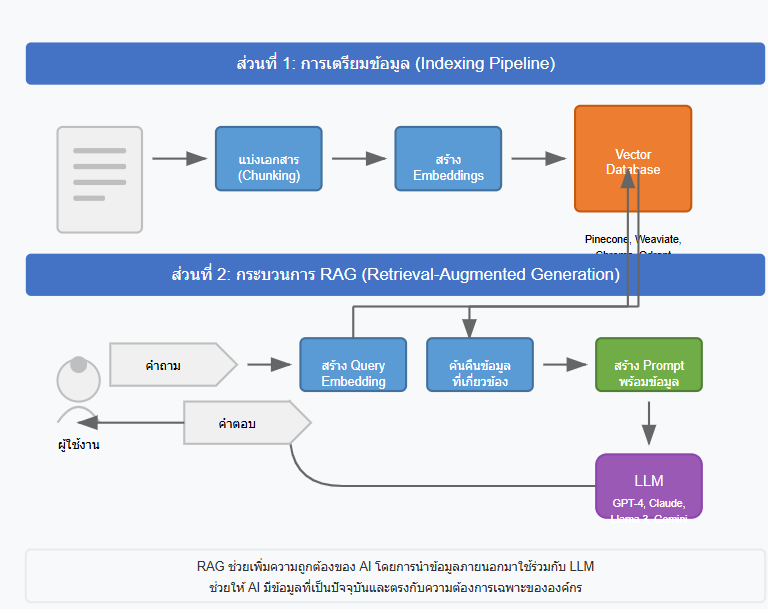
หลักการทำงานของ RAG มีดังนี้
- การค้นคืนข้อมูล (Retrieval): ระบบจะค้นหาเอกสารหรือข้อมูลที่เกี่ยวข้องกับคำถามจากฐานความรู้ภายนอก เช่น เอกสารองค์กร บทความ หรือฐานข้อมูลเฉพาะทาง
- การสร้างข้อความ (Generation): นำข้อมูลที่ค้นคืนมาได้มาใช้เป็นบริบท (context) เพิ่มเติมให้กับโมเดลภาษา เพื่อสร้างคำตอบที่เกี่ยวข้องและถูกต้อง
ประโยชน์หลักของ RAG:
- ลดการสร้างข้อมูลผิดพลาด (hallucination) เนื่องจากคำตอบอ้างอิงจากข้อมูลจริง
- ให้ข้อมูลที่เป็นปัจจุบัน โดยไม่ถูกจำกัดด้วยข้อมูลที่ใช้ในการฝึกโมเดล
- สามารถอ้างอิงแหล่งที่มา ของข้อมูลได้
- ปรับให้เข้ากับข้อมูลเฉพาะทาง ขององค์กรหรือโดเมนที่เฉพาะเจาะจงได้
ตัวอย่างการใช้งาน RAG:
- ระบบช่วยเหลือลูกค้าที่สามารถตอบคำถามจากเอกสารภายในองค์กร
- ระบบค้นหาข้อมูลทางการแพทย์ที่อ้างอิงจากงานวิจัยล่าสุด
- ผู้ช่วยอัจฉริยะที่สามารถให้ข้อมูลที่เป็นปัจจุบันจากแหล่งข้อมูลหลากหลาย
โดยสรุป RAG เป็นเทคนิคที่ช่วยให้ AI มีความสามารถในการเข้าถึงข้อมูลภายนอกเพื่อให้คำตอบที่มีความถูกต้องและน่าเชื่อถือมากขึ้น
การรักษาความเป็นส่วนตัวของข้อมูล
ข้อมูลที่ใช้ในการ Augment สามารถเก็บไว้ภายในองค์กรได้ ทำให้มั่นใจในความปลอดภัยและความเป็นส่วนตัว Red Hat กล่าวว่า RAG สามารถคงข้อมูลที่ละเอียดอ่อนไว้ภายในองค์กรได้ และยังคงสามารถนำมาใช้เพื่อให้ข้อมูลแก่ LLM ได้ NVIDIA กล่าวว่าผู้ใช้สามารถ Link ไปยังแหล่งความรู้ส่วนตัวบน PC ได้อย่างปลอดภัย Salesforce กล่าวว่า RAG ช่วยให้บริษัทต่างๆ สามารถเชื่อมต่อข้อมูลของตนเองกับ LLMs ได้อย่างปลอดภัย DataMotion กล่าวว่า RAG ช่วยรักษาความปลอดภัยของข้อมูลที่ละเอียดอ่อนโดยการเก็บข้อมูลไว้นอก Model Oracle กล่าวว่า RAG มีความปลอดภัยด้านข้อมูลและความเป็นส่วนตัวสูงกว่าการ Fine-tuning เนื่องจากข้อมูลสามารถจัดเก็บในสภาพแวดล้อมที่ปลอดภัยพร้อมการควบคุมการเข้าถึงที่เข้มงวด Monte Carlo Data กล่าวว่า RAG ช่วยให้ข้อมูลที่เป็นกรรมสิทธิ์ของคุณอยู่ในสภาพแวดล้อมฐานข้อมูลที่ปลอดภัยของคุณ ทำให้สามารถควบคุมการเข้าถึงได้อย่างเข้มงวด
ข้อดีมากมายของ RAG เหล่านี้ช่วยแก้ไขข้อบกพร่องพื้นฐานของ LLMs แบบ Standalone ทำให้เป็นโซลูชันที่มีคุณค่าและใช้งานได้จริงสำหรับการปรับปรุงความน่าเชื่อถือ ความถูกต้อง และความสามารถในการใช้งานในหลากหลายแอปพลิเคชันในโลกแห่งความเป็นจริง
ความสามารถของ RAG ในการรักษาความเป็นส่วนตัวและความปลอดภัยของข้อมูลในขณะที่ยังคงใช้ประโยชน์จากความรู้ภายนอกได้นั้นเป็นข้อได้เปรียบที่สำคัญ โดยเฉพาะอย่างยิ่งสำหรับองค์กรที่จัดการกับข้อมูลที่ละเอียดอ่อนในอุตสาหกรรมที่มีการควบคุม ในขณะที่การ Fine-tuning มักเกี่ยวข้องกับการรวมข้อมูลส่วนตัวเข้ากับ LLM เอง ซึ่งก่อให้เกิดความกังวลเกี่ยวกับการเปิดเผยข้อมูล RAG อนุญาตให้ข้อมูลที่ละเอียดอ่อนยังคงอยู่ในสภาพแวดล้อมที่ปลอดภัยขององค์กร ในขณะที่ยังคงเปิดใช้งาน LLM เพื่อเข้าถึงและใช้ข้อมูลนี้ในการสร้างการตอบสนอง ความสามารถนี้มีความสำคัญอย่างยิ่งต่อการปฏิบัติตามข้อกำหนดและการรักษาความลับของข้อมูลที่เป็นกรรมสิทธิ์หรือข้อมูลลูกค้า
ข้อเสียของการใช้ Retrieval-Augmented Generation
แม้ว่า Retrieval-Augmented Generation (RAG) จะมีข้อดีมากมาย แต่ก็มีข้อเสียบางประการที่ควรพิจารณาในการนำไปใช้งาน
ความซับซ้อนในการติดตั้งและจัดการระบบ
การตั้งค่าและดูแลรักษาระบบ RAG อาจมีความซับซ้อน เนื่องจากต้องมีการจัดการทั้งส่วนของการดึงข้อมูลและการสร้างข้อความ Superannotate กล่าวว่า RAG ต้องการฐานข้อมูลขนาดใหญ่ของข้อมูลที่ Pre-processed ซึ่งอาจต้องใช้ทรัพยากรมาก นอกจากนี้ การตั้งค่าและดูแลรักษาฐานข้อมูลเหล่านี้เกี่ยวข้องกับการโต้ตอบที่ซับซ้อนและอาจมี Latency เพิ่มเติมระหว่างระบบ Arcee AI กล่าวว่าการ Implement ระบบ RAG เกี่ยวข้องกับการจัดการทั้ง Generation Model และ Retriever Component ซึ่งอาจซับซ้อนกว่าการ Fine-tuning แบบมาตรฐาน AIMind กล่าวว่า RAG มีส่วนประกอบที่ต้องจัดการมากกว่า เช่น การ Index และจัดเก็บ Vector Data, ส่วนประกอบ Retrieval และ Generation Vellum AI กล่าวว่า RAG Pipeline ทั่วไปมีส่วนประกอบจำนวนมาก (Indexing, Retriever, Generator) ทำให้เกิดความซับซ้อนเพิ่มเติม Monte Carlo Data กล่าวว่าการพัฒนา RAG เป็นกระบวนการที่ซับซ้อน และอาจเกี่ยวข้องกับ Prompt Engineering, Vector Databases, Embedding Vectors, Data Modeling, Data Orchestration, และ Data Pipelines Glean กล่าวว่าการปรับขนาดระบบ RAG สำหรับ Dataset ที่ใหญ่ขึ้นหรือแอปพลิเคชันที่ซับซ้อนมากขึ้นอาจนำไปสู่ความท้าทายด้าน Computational และ Cost-related Chitika กล่าวว่าการรวม Retrieval และ Generation เป็นเหมือนการ Sync วงออเคสตรา และความไม่สอดคล้องกันอาจนำไปสู่ Output ที่ไม่สมเหตุสมผล
นอกจากนี้ ต้องมีโครงสร้างพื้นฐานที่แข็งแกร่งเพื่อรองรับการดึงข้อมูลแบบ Real-time Glean กล่าวว่าความต้องการโครงสร้างพื้นฐานที่แข็งแกร่งเพื่อรองรับการดึงข้อมูลแบบ Real-time อาจเพิ่มค่าใช้จ่ายในการดำเนินงาน
ปัญหาด้าน Latency ที่อาจเกิดขึ้นจากการดึงข้อมูล
กระบวนการดึงข้อมูลจากภายนอกอาจทำให้เกิดความล่าช้าในการตอบสนอง (Latency) Superannotate กล่าวว่าการโต้ตอบที่ซับซ้อนระหว่างระบบอาจมาพร้อมกับ Latency เพิ่มเติมระหว่างระบบ Vellum AI กล่าวว่าขั้นตอนเพิ่มเติมที่เกี่ยวข้องในกระบวนการ RAG มีแนวโน้มที่จะส่งผลให้ Latency สูงขึ้น Medium กล่าวว่าขั้นตอนการดึงข้อมูลของ RAG จะเพิ่ม Latency ในการ Inference Chitika กล่าวว่าการดึงข้อมูลแบบ Real-time ของ RAG อาจทำให้เกิดปัญหา Latency ได้
ความจำเป็นในการมีข้อมูลคุณภาพสูงและมีการปรับปรุงอย่างต่อเนื่อง
ประสิทธิภาพของ RAG ขึ้นอยู่กับคุณภาพและความเกี่ยวข้องของข้อมูลที่ดึงมา McKinsey กล่าวว่าคุณภาพของ Output ขึ้นอยู่กับคุณภาพของข้อมูลที่เข้าถึง Superannotate กล่าวว่า RAG ต้องการฐานข้อมูลขนาดใหญ่ของข้อมูลที่ Pre-processed Vellum AI กล่าวว่า RAG ทำงานได้ดีที่สุดเมื่อมีข้อมูลภายนอกจำนวนมาก แต่มีความรู้ภายนอกที่เกี่ยวข้อง ทำให้เหมาะสำหรับ Tasks ที่มีข้อมูลเฉพาะ Task น้อยหรือไม่แพง DBTA กล่าวว่าความกังวลเรื่องคุณภาพข้อมูลเป็นปัญหาอันดับต้นๆ ที่องค์กรเผชิญกับ GenAI และการ Implement LLM Glean กล่าวว่าความท้าทายหลักประการหนึ่งสำหรับ RAG Models คือการรับประกันคุณภาพข้อมูลที่สูง Chitika กล่าวว่าหากฐานความรู้มี Bias หรือล้าสมัย RAG จะขยายข้อบกพร่องเหล่านี้ arXiv กล่าวว่ากลไกการดึงข้อมูลอาจยังคงมีปัญหาในการดึงเอกสารที่เกี่ยวข้องมากที่สุด โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับ Queries ที่คลุมเครือหรือ Domain ความรู้เฉพาะทาง
ข้อมูลที่ล้าสมัยหรือไม่ถูกต้องจะส่งผลเสียต่อผลลัพธ์ Google Cloud กล่าวว่า LLMs ถูกจำกัดด้วยข้อมูลการฝึกฝน ทำให้คำตอบอาจล้าสมัย AWS กล่าวว่าข้อมูลการฝึกฝนของ LLMs เป็นแบบ Static และมีวันหมดอายุ IBM ยกตัวอย่างปัญหาข้อมูลล้าสมัยของ LLMs Red Hat กล่าวว่าข้อมูลของ Model อาจล้าสมัยและต้องมีการ Retrain Superannotate กล่าวว่า RAG ใช้ข้อมูลล่าสุดจากแหล่งต่างๆ
ต้องมีการดูแลรักษาและอัปเดตฐานข้อมูลความรู้อย่างสม่ำเสมอ AWS กล่าวว่าข้อมูลภายนอกต้องได้รับการอัปเดตแบบ Asynchronous Red Hat กล่าวว่า Model ที่ Fine-tune แล้วจะต้องมีการ Retrain เป็นระยะเพื่อให้ทันสมัยอยู่เสมอ Superannotate กล่าวว่า RAG จะอัปเดตตัวเองด้วยข้อมูลใหม่ ทำให้ลดภาระงานของนักพัฒนา Glean กล่าวว่าการจัดการ Repository ข้อมูลที่ใหญ่ขึ้นและมีความหลากหลายมากขึ้นอาจทำให้การดึงข้อมูล, การอัปเดต, และการบำรุงรักษายุ่งยาก Chitika กล่าวว่าการอัปเดตเป็นประจำและเครื่องมือตรวจจับ Anomalies มีความจำเป็นต่อการรักษาความน่าเชื่อถือ
| Feature | Retrieval-Augmented Generation (RAG) | Fine-tuning Large Language Models (LLMs) |
| วัตถุประสงค์ | เสริม LLMs ด้วยข้อมูลภายนอกที่ทันสมัย ณ เวลา Inference | ปรับ LLMs ที่ฝึกฝนมาแล้วให้เหมาะกับ Tasks หรือ Domains เฉพาะทางผ่านการฝึกเพิ่มเติม |
| ความต้องการข้อมูล | ต้องการการเข้าถึงฐานความรู้ภายนอก (อาจเป็นข้อมูลที่ไม่มีโครงสร้าง) | ต้องการ Dataset ที่มีการจัดทำและติดป้ายกำกับเฉพาะสำหรับ Task ที่ต้องการ |
| ค่าใช้จ่าย | โดยทั่วไปมีค่าใช้จ่ายเริ่มต้นต่ำกว่า อาจมีค่าใช้จ่ายในการดำเนินงานสำหรับโครงสร้างพื้นฐานการดึงข้อมูล | อาจมีค่าใช้จ่ายด้านการคำนวณสูง ต้องใช้ทรัพยากรจำนวนมากสำหรับการฝึกฝน |
| ความถี่ในการอัปเดต | รองรับการอัปเดตแบบ Real-time โดยการแก้ไขฐานความรู้ภายนอก | ต้องมีการ Retrain เป็นระยะเพื่อรวมข้อมูลใหม่ |
| ความแม่นยำ | ปรับปรุงความแม่นยำโดยการอ้างอิงคำตอบจากข้อมูลภายนอก ลด Hallucinations | ปรับปรุงความแม่นยำสำหรับ Tasks เฉพาะทางภายใน Domain ที่ทำการฝึกฝน |
| Hallucinations | มีแนวโน้มที่จะเกิด Hallucinations น้อยกว่าเนื่องจากการอิงข้อมูลที่ดึงมา | ยังคงสามารถเกิด Hallucinations ได้ โดยเฉพาะอย่างยิ่งกับ Queries ที่ไม่คุ้นเคย |
| ความซับซ้อน | อาจเกี่ยวข้องกับการบูรณาการระบบที่ซับซ้อนสำหรับการดึงข้อมูล | ต้องการความเชี่ยวชาญด้าน NLP, Deep Learning, และการกำหนดค่า Model |
| กรณีใช้งานที่ดีที่สุด | การจัดการข้อมูลที่อัปเดตบ่อยครั้ง ต้องการข้อมูลแบบ Real-time Tasks ที่ต้องใช้ความรู้เฉพาะทาง | แอปพลิเคชันเฉพาะทาง Tasks ที่ต้องการความเชี่ยวชาญใน Domain อย่างลึกซึ้ง การวิเคราะห์ความรู้สึก |